The aI Scientist: in the Direction Of Fully Automated Open-Ended Scien…
페이지 정보

본문
 This is cool. Against my non-public GPQA-like benchmark deepseek v2 is the actual greatest performing open source mannequin I've tested (inclusive of the 405B variants). In a current publish on the social community X by Maziyar Panahi, Principal AI/ML/Data Engineer at CNRS, the model was praised as "the world’s best open-supply LLM" in accordance with the DeepSeek team’s printed benchmarks. It actually rizzed me up when I was proof-reading for a earlier weblog submit I wrote. XTuner is able to fine-tuning 7B LLM on a single 8GB GPU, as well as multi-node nice-tuning of fashions exceeding 70B. - Automatically dispatch excessive-performance operators akin to FlashAttention and Triton kernels to extend coaching throughput. Available in each English and Chinese languages, the LLM goals to foster research and innovation. For a deeper dive and a more detailed description of the research by the JetBrains Research team, read the Kotlin ML Pack: Technical Report. Hermes-2-Theta-Llama-3-8B is a chopping-edge language mannequin created by Nous Research. Natural language excels in abstract reasoning but falls quick in precise computation, symbolic manipulation, and algorithmic processing. We noted that LLMs can carry out mathematical reasoning utilizing both textual content and packages.
This is cool. Against my non-public GPQA-like benchmark deepseek v2 is the actual greatest performing open source mannequin I've tested (inclusive of the 405B variants). In a current publish on the social community X by Maziyar Panahi, Principal AI/ML/Data Engineer at CNRS, the model was praised as "the world’s best open-supply LLM" in accordance with the DeepSeek team’s printed benchmarks. It actually rizzed me up when I was proof-reading for a earlier weblog submit I wrote. XTuner is able to fine-tuning 7B LLM on a single 8GB GPU, as well as multi-node nice-tuning of fashions exceeding 70B. - Automatically dispatch excessive-performance operators akin to FlashAttention and Triton kernels to extend coaching throughput. Available in each English and Chinese languages, the LLM goals to foster research and innovation. For a deeper dive and a more detailed description of the research by the JetBrains Research team, read the Kotlin ML Pack: Technical Report. Hermes-2-Theta-Llama-3-8B is a chopping-edge language mannequin created by Nous Research. Natural language excels in abstract reasoning but falls quick in precise computation, symbolic manipulation, and algorithmic processing. We noted that LLMs can carry out mathematical reasoning utilizing both textual content and packages.
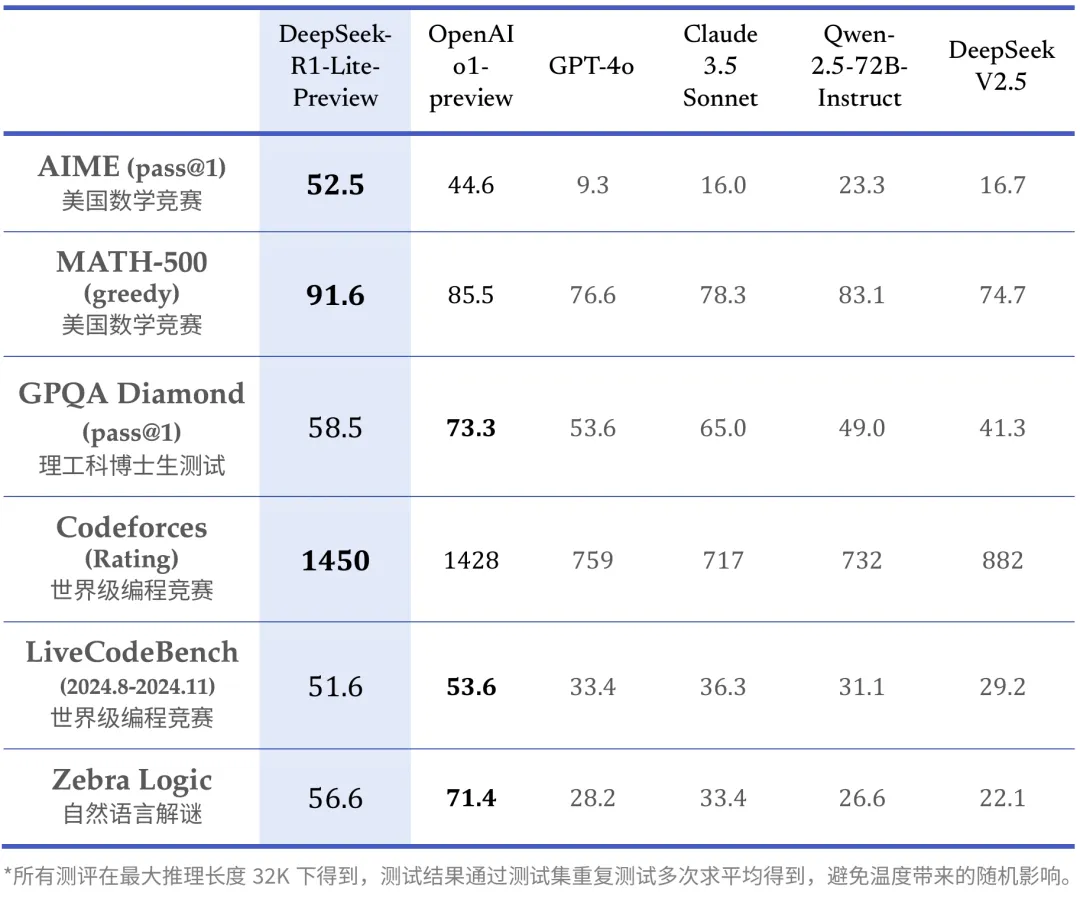 And i find myself wondering: if utilizing pinyin to put in writing Chinese on a cellphone means that Chinese speakers are forgetting how to put in writing Chinese characters without digital aids, what will we lose when we get in the behavior of outsourcing our creativity? It will likely be higher to mix with searxng. We moved the announcement date for 2024 Prizes from December three to December 6, 2024 to raised align with NeurIPS. As a CoE, the mannequin is composed of a number of various smaller models, all working as if it had been one single very large mannequin. Their chips are designed round a concept referred to as "deterministic compute," which implies that, in contrast to conventional GPUs the place the precise timing of operations can fluctuate, their chips execute operations in a very predictable means every single time. 3. What can DeepSeek-V3 do? 9. How can I present suggestions or report a problem with DeepSeek-V3? By following these steps, you can simply combine a number of OpenAI-compatible APIs along with your Open WebUI occasion, unlocking the complete potential of these powerful AI fashions. Claude 3.5 Sonnet has proven to be the most effective performing models out there, and is the default model for our Free and Pro customers.
And i find myself wondering: if utilizing pinyin to put in writing Chinese on a cellphone means that Chinese speakers are forgetting how to put in writing Chinese characters without digital aids, what will we lose when we get in the behavior of outsourcing our creativity? It will likely be higher to mix with searxng. We moved the announcement date for 2024 Prizes from December three to December 6, 2024 to raised align with NeurIPS. As a CoE, the mannequin is composed of a number of various smaller models, all working as if it had been one single very large mannequin. Their chips are designed round a concept referred to as "deterministic compute," which implies that, in contrast to conventional GPUs the place the precise timing of operations can fluctuate, their chips execute operations in a very predictable means every single time. 3. What can DeepSeek-V3 do? 9. How can I present suggestions or report a problem with DeepSeek-V3? By following these steps, you can simply combine a number of OpenAI-compatible APIs along with your Open WebUI occasion, unlocking the complete potential of these powerful AI fashions. Claude 3.5 Sonnet has proven to be the most effective performing models out there, and is the default model for our Free and Pro customers.
DeepSeek v3 v2 Coder and Claude 3.5 Sonnet are more cost-effective at code generation than GPT-4o! We’ve seen improvements in overall user satisfaction with Claude 3.5 Sonnet across these customers, so on this month’s Sourcegraph launch we’re making it the default model for chat and prompts. Besides its market edges, the corporate is disrupting the status quo by publicly making educated fashions and underlying tech accessible. You don't need to pay OpenAI for the privilege of working their fancy models. And as always, please contact your account rep when you've got any questions. I'm wondering if this approach would assist rather a lot of those sorts of questions? This approach combines natural language reasoning with program-primarily based problem-fixing. The coverage model served as the primary downside solver in our method. This technique stemmed from our study on compute-optimal inference, demonstrating that weighted majority voting with a reward mannequin consistently outperforms naive majority voting given the same inference budget.
Our last options have been derived by a weighted majority voting system, the place the answers had been generated by the coverage model and the weights were determined by the scores from the reward mannequin. Our closing dataset contained 41,160 downside-solution pairs. Later in inference we are able to use those tokens to offer a prefix, suffix, and let it "predict" the center. At every consideration layer, information can move forward by W tokens. This means you should use the expertise in commercial contexts, together with selling services that use the model (e.g., software program-as-a-service). A promising course is the use of giant language fashions (LLM), which have proven to have good reasoning capabilities when skilled on giant corpora of textual content and math. The sweet spot is the highest-left nook: low cost with good outcomes. Benchmark results show that SGLang v0.3 with MLA optimizations achieves 3x to 7x increased throughput than the baseline system. DeepSeek-V2.5’s architecture includes key improvements, comparable to Multi-Head Latent Attention (MLA), which considerably reduces the KV cache, thereby enhancing inference speed with out compromising on model performance. He expressed his shock that the model hadn’t garnered more attention, given its groundbreaking performance. The DeepSeek model license permits for commercial utilization of the know-how beneath specific situations.
If you have any type of concerns concerning where and the best ways to use deepseek français, you can contact us at our web site.
- 이전글Shocking Details About Deepseek Ai Exposed 25.03.15
- 다음글Двери экошпон в казани 25.03.15
댓글목록
등록된 댓글이 없습니다.